一、前言
前段时间老大说想对驱动做下benchmark,主要有如下几个原因:
1、在(灰度)推广前对驱动在跟踪特定syscall event下的overhead(开销)有大致的了解,从而对某些造成tracepoint handler较高overhead的syscall tracepoint采取默认关闭策略,避免对业务产生影响
2、字节之前开源的Elkeid(前Agent-smith)中有输出driver的性能测试报告,可以与其做下对比,也好有个底(字节的驱动部署量级很高)
目标确定后开始测试流程,一开始是参照Elkeid使用trace-cmd(ftrace) + LTP测TP90/95/99(Top Percentile),结果发现Elkeid的测试方式这边并不适用(主要是因为elkeid采用了kprobe选型,针对每一个syscall都有特定的kprobe handler,这些注册的hook函数可以被ftrace跟踪到;但是这边的驱动走的是tracepoint,而且是在sys_enter/sys_exit的系统调用总出入口处做的hook,所以在ftrace的观测视野中,只能看到对sys_enter/sys_exit对应tracepoint handler的执行耗时,但却没有办法将其对应到指定系统调用事件),中途踩了许多坑(主要是验证测试方式及数据可靠性上的,甚至一度放弃ftrace使用perf与systemtap,但是最终对比之下还是回到了ftrace上),甚至在测试过程中发现Elkeid自身的测试方式可能存在问题,过程还挺曲折//捂脸,最终将测试过程自动化,输出了一份性能测试报告;当然这些扯远了。之所以想记录这篇文章,主要是在测试过程中感受到了ftrace能力的强大,不仅可用于性能分析,还可以在日常研究学习中用于内核函数/代码执行流程观测,来代替动态调试的繁琐(当然主要还是得看场景,动调也有其自己的优势,但是如果只是想看控制流的话ftrace还是非常方便的),甚至ftrace从功能上来说本身都可直接用于IDS上(kprobe on ftrace的一些高级用法);此篇主要记录ftrace观测kprobe和tracepoint函数的过程,目的主要是1、记录ftrace的使用方式 方便后面回忆 2、以可视化的方式(graph)展示kprobe与tracepoint的执行流程,加深对这两种机制的记忆与理解。
二、原理
Ftrace是linux内核集成的帮助开发人员了解LInux内核运行时行为的工具,以便于进行调试和故障分析。Ftrace的实现是这样的,首先在linux内核编译的时候利用gcc -pg的特性在每个函数头部增加(默认mcount)函数调用,考虑到在每一个内核函数头部都添加额外的执行逻辑会大大增加内核的消耗,所以ftrace使用动态插桩的模式来实现功能,具体是这样的:在内核初始化的时候,ftrace会查询并获取添加的(mcount)插桩函数的所有地址,并将其替换为nop指令,这样在默认情况下就不会对系统内核产生性能影响。当需要进行跟踪时,根据相关设置(set_ftrace、function_graph等)将特定nop指令动态替换为跳转指令(ftrace_caller)实现动态跟踪。
放张架构图:
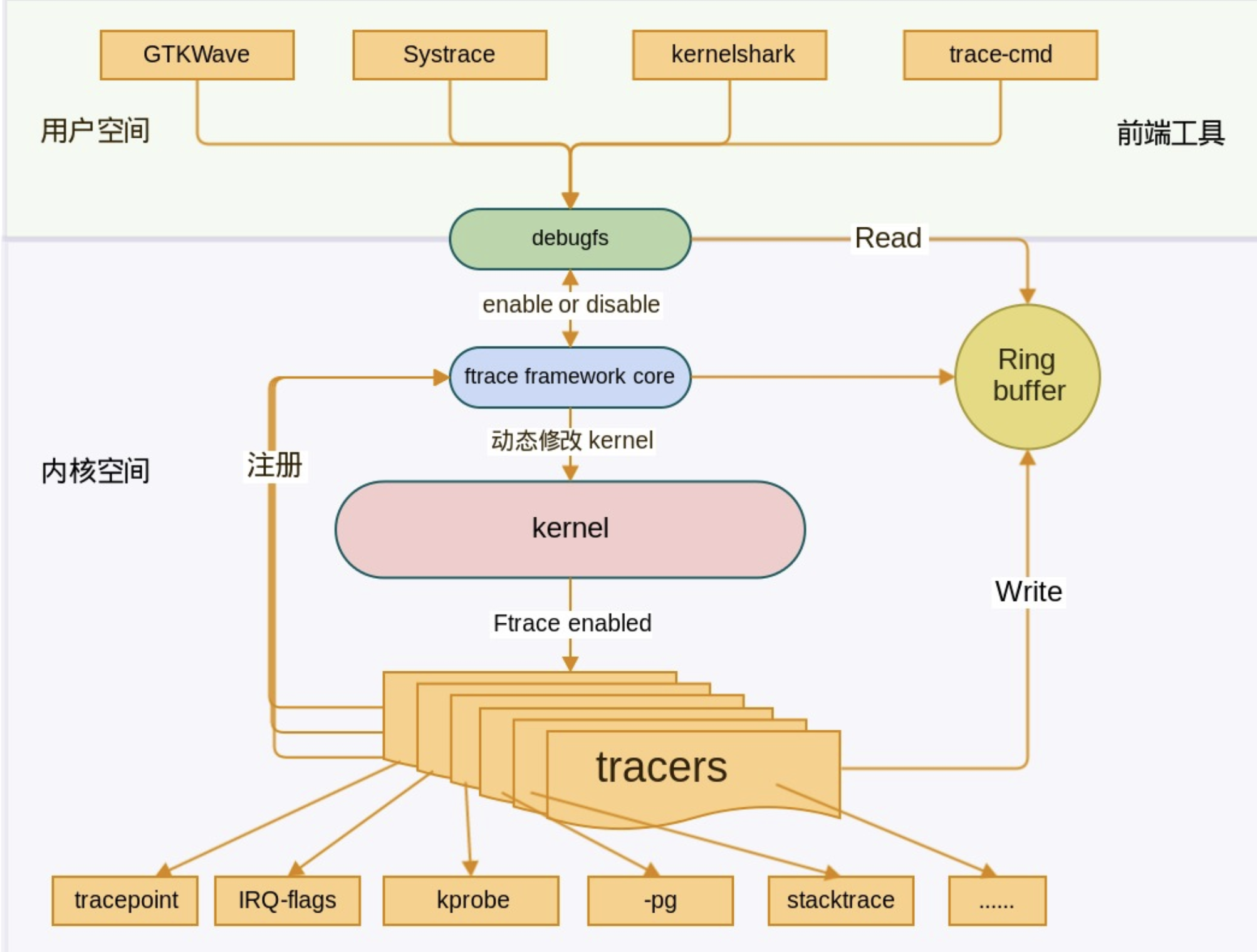
三、使用
1、观测
原生的ftrace操作起来比较烦琐,前端工具trace-cmd封装了相关读写文件的操作,比较方便:
1 | insmod lkm.ko |
2、分析
tracepoint:
安装驱动后抓取指定进程的全量内核函数调用栈五秒,如图,可以看到函数调用关系很清晰的展现出来了,比如系统调用内部函数层级和执行流程,tracepoint handler执行流程,tracepoint上层函数调用关系等等。调用关系:syscall_trace_enter -> [tracepoint_enter_probe_handler] -> syscall_event -> sys call_trace_leave -> [tracepoint_exit_probe_handler]
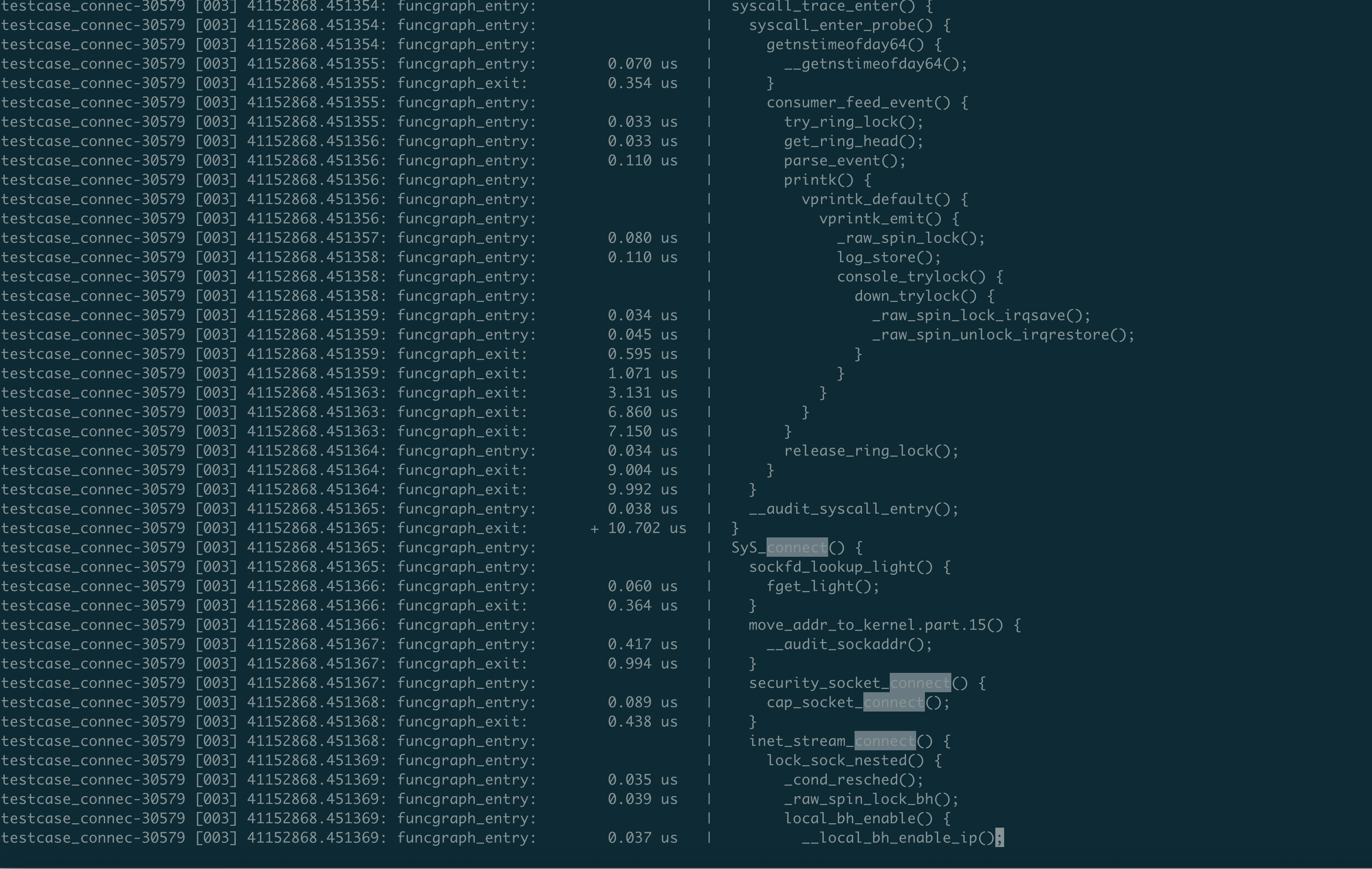
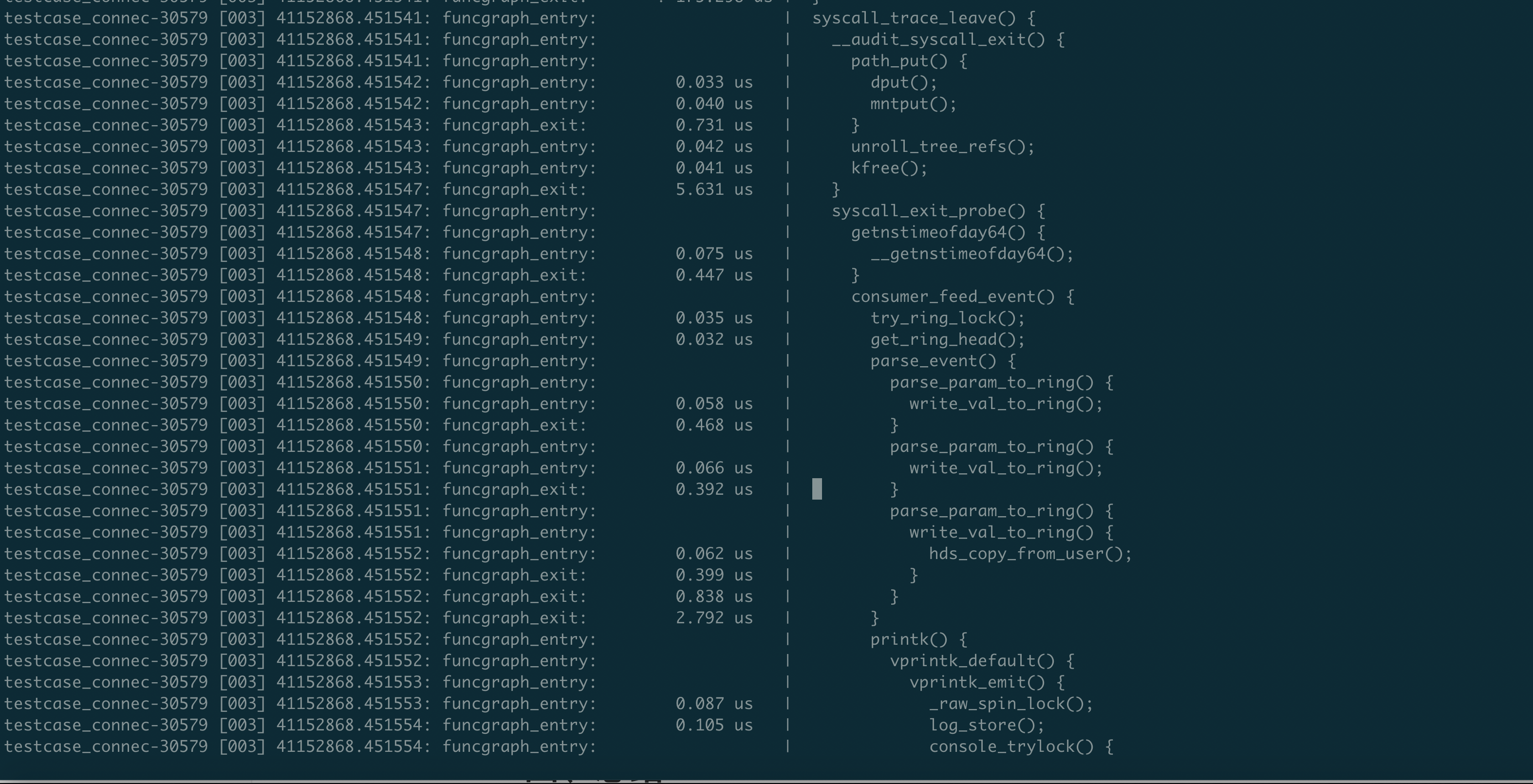
kprobe:
调用关系:get_kprobe -> pre_handler_kretprobe -> [syscall_entry_handler] -> syscall_event -> trampoline_handler -> [syscall_handler]
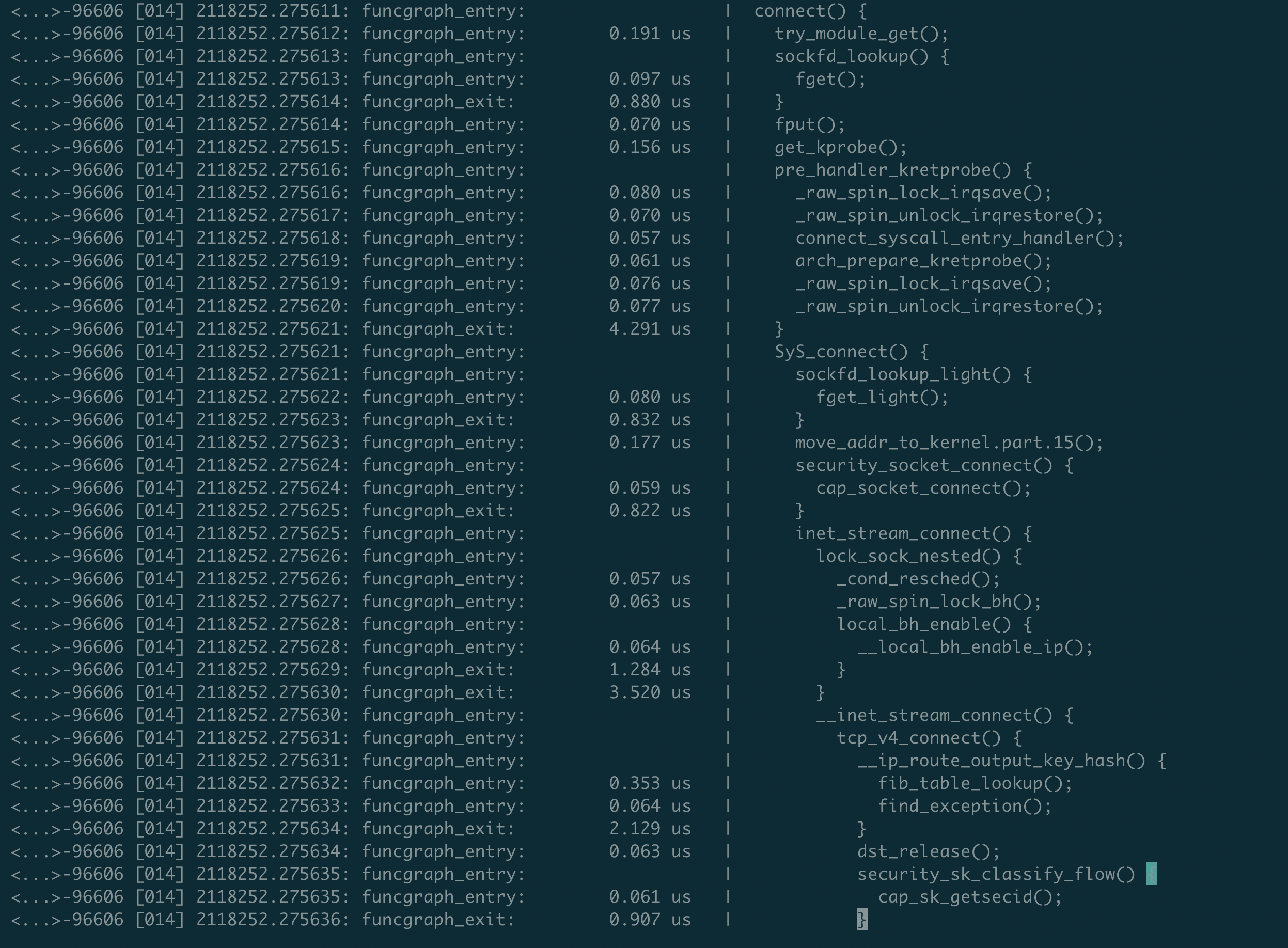
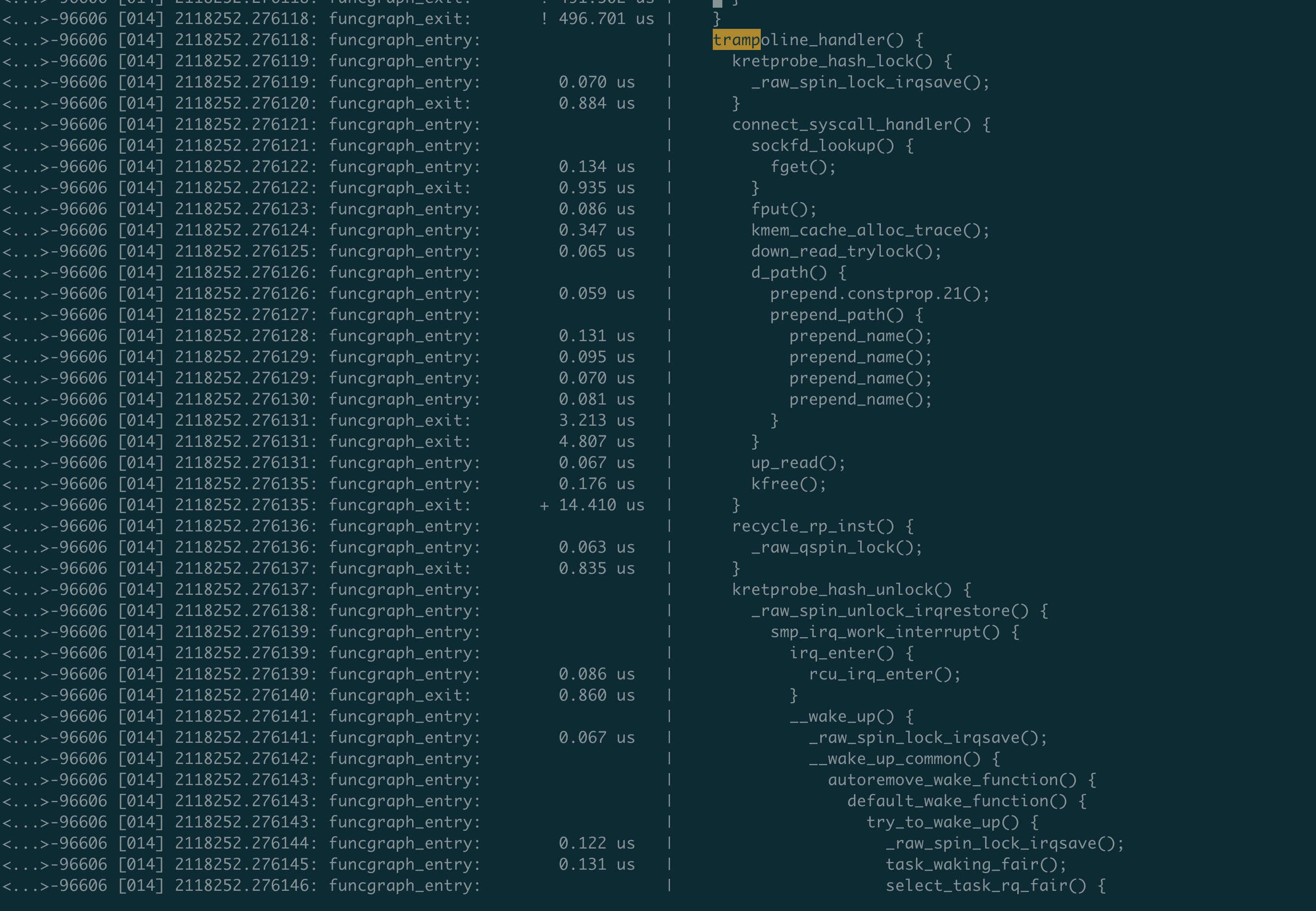
可以将function_graph与kprobe/tracepoint相关文档定义、内核源码结合分析,加深理解。
3、踩坑
1)ftrace抓取log中的内核函数可能并不连续,实际上连续的执行流程可能分布在多个cpu上,可以通过grep指定cpu/进程id进行归类
2)抓取的内核函数越多,cpu耗时越长(ftrace探针放置太多的原因),可以通过过滤指定内核函数来保证抓取的执行耗时的精确性
3)不同内核版本符号很可能不同,比如3.10上ftrace可以抓的系统调用函数是SyS_execve,到了5.x的机器上就变成了__x64_sys_execve,可以通过查看/proc/kallsyms或抓ftrace一次全量数据来定位
4)etc.
四、总结
将之前项目中学习到的东西进行了一些记录,包括ftrace的原理、使用以及krpobe、tracepoint这两种监控领域主流技术选型在ftrace下执行流程的观测。后面如果有时间会把性能测试过程中用到的其他工具也单独写文章记录,如perf(吹爆火焰图)、systemtap(更细粒度)等等。
五、参考
http://hushi55.github.io/2015/10/28/linux-ftrace
https://zhuanlan.zhihu.com/p/355246942
https://richardweiyang-2.gitbook.io/kernel-exploring/00-index-3/04-ftrace_internal