引子
从入CTF这个大坑以来,读过不少书,要说印象最深刻,非程序员的自我修养这本书莫属。为何非钟情此书,因为这本书真正带我突破瓶颈,步入底层的世界。刚入手的时候发现内容晦涩难以下咽,越往后看越难以理解,但是不得不承认这本书有着神奇的吸引力,让当时的我一次次放下,又一次次拿起,磕磕绊绊之下,对程序的运行原理也算是有个一个大概。下面打算根据自己的理解大概讲讲程序从编写到装载执行的过程
0x01 预处理
源代码编写完交给编译器进行编译时,编译器首先会进行预处理操作,源代码和相关的头文件会被整合到一起,构成一个后缀为.i的文件,其中主要内容有:
gcc -E main.c -o main.i #预编译,生成main.i文件
0x02 编译
编译过程是整个编译器所做最复杂也是最重要的部分,主要包括如下几个部分:
- 扫描器收录:源代码被收录进扫描器
- 词法分析:分析代码词句是否有错误
- 语法分析:分析代码语法是否有错误
- 语义分析:分析代码语法是否有意义
- 优化:生成中间语言并进行优化
- 汇编代码生成与优化:删除多余指令、使用位移来代替乘法运算等
gcc -S main.i #编译,生成main.S文件
0x03 汇编
汇编是将汇编代码转变成机器指令的过程,相对于编译,这个过程要简单很多。可以理解成编译器中内置了一张汇编与机器字节码的对应表,汇编到机器指令的过程本质上就是根据编译生成汇编代码在编译器中一条一条翻译过来的过程。
gcc -c main.S #汇编,生成main.o文件
0x04 链接
当一个模块中引用了另一个模块中的符号时,就需要链接,链接就是把各个模块相互引用的部分都处理好,使得各个模块间都能正确的衔接。链接的过程其实也就是抽象层的符号与底层地址之间的转换过程。
举个例子,如果在main中引用了另一个模块中的函数func(),我们必须知道func函数的地址,否则程序是无法找到并执行那串代码的,但是由于每个模块都是单独编译,因此在编译main的时候并不知道func函数的地址,所以编译main的时候暂时将调用func函数地址的代码操作数搁置,等链接的时候再进行修正。这个过程中,对所有引用的外部函数进行查找定义的过程,叫做符号解析,调用func函数地址进行修正的过程,就叫重定位。具体操作如下:
(1)符号解析
当引用外部函数的时候,首先需要找到这个被引用的函数,确定它的目标地址,这时链接器就会去目标文件的符号表进行查找,能找到则返回引用位置进行重定位,找不到则报错。
(2)重定位
一旦链接器完成了符号解析这一步,它就把代码中每个符号引用和一个确定的符号定义联系了起来。此时,链接器就知道了每个模块(文件)代码节和数据节的大小,就可以开始重定位了。
重定位由两步组成:
- 重定位节和符号定义。聚合可重定位目标文件中相同的节。并且为每个节和符号分配虚拟地址。
- 重定位节中的符号引用。
汇编器将本地没有定义的符号写入可重定位目标文件的.symtab表,让链接器到其它可重定位目标文件中查找。同理,汇编器遇到对存储位置未知(在可重定位目标文件中,汇编器都不知道数据和代码会存放在存储器的什么位置)的符号引用时,它也会将这些符号的信息存于.rel.text和.rel.data表中。告诉链接器将可重定位目标文件合并成可执行目标文件时如何修改引用。
gcc main.o -o main #链接,生成可执行文件
0x05 装载
程序链接完成后需要被载入内存,这个过程由装载器loader进行接管。主要分为如下几步:
- 创建虚拟内存到磁盘文件之间的映射(存储器映射)
- 创建虚拟地址到物理内存的映射,创建目录和页表
- 加载数据段、代码段
- 把可执行文件入口地址写入CPU的PC
说到装载,这边必须说一下虚拟内存。
虚拟内存
概念:虚拟内存是磁盘开辟空间作为内存的一个补充。进程可以一部分留在物理内存中,其它部分存储在虚拟内存中。
优点:1、同时执行的进程数大大增加 2、可以执行比内存空间大的进程 3、程序中访问的都是虚拟地址空间,无法直接访问物理地址,更安全虚拟内存布局
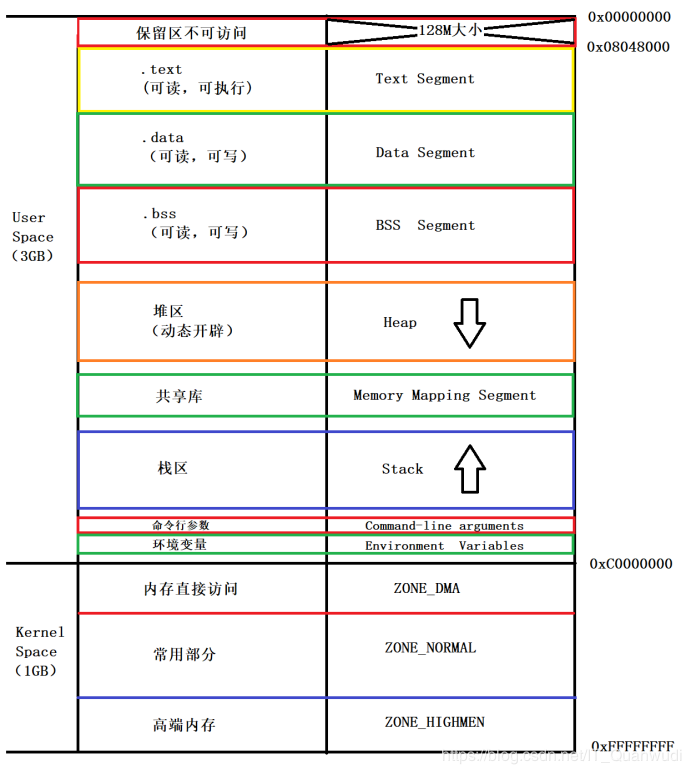
32位操作系统下,每个进程能寻址2^32个地址空间,也就是4G,这个虚拟空间包含独立的3G用户空间和所有进程共享的1G内核空间。
开头128M字节的的区域为不可访问区(保留区),通常将申请的临时指针变量初始化为NULL防止引用出错,NULL==0x00,指针指向的保留区没有访问权限。
理解:
- 每个进程的4G内存空间只是虚拟地址,每次访问内存空间的某个地址,都需要把地址翻译为实际物理内存地址
- 所有进程共享同一物理内存,每个进程只把自己当前需要的虚拟内存映射到物理内存上
- 进程要知道那些虚拟内存中的数据在物理内存上,哪些不在,还有在物理内存上的哪里,需要用页表来记录
- 页表的每一个表项分为两个部分,第一部分记录此页是否在物理内存上,第二部分记录物理内存页地址(如果在的话)
- 当进程访问某个虚拟地址,去看页表,如果发现对应数据不在物理内存中,则缺页异常
- 缺页异常的处理过程,就是把进程需要的数据从磁盘上拷贝到物理内存中,如果此时内存已经满了,没有空余空间给放置,那就找一个页覆盖,当然如果被覆盖的页曾经被修改过,则需要将此页写会磁盘
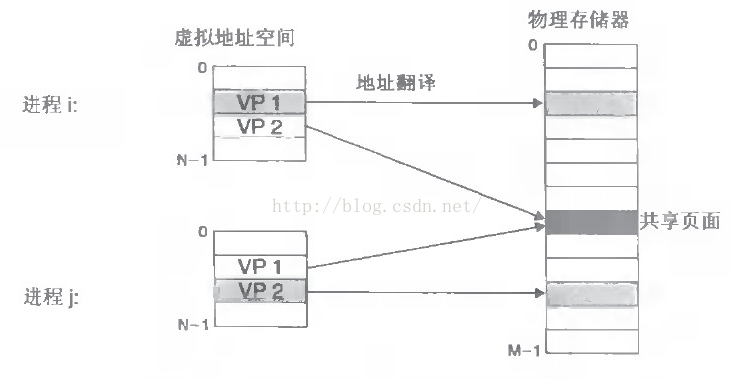
虚拟地址空间和物理地址空间对应:虚拟地址空间指的是进程可寻址的地址空间范围,而物理地址空间指的是实际可用地址空间范围。
优点:
- 每个进程的虚拟内存空间都是一致而且固定的,所以链接器在链接可执行文件的时候,不用去管数据实际加载到的内存地址
- 不同进程使用相同的代码时,比如库文件中的代码,物理内存中只存储一份这样的代码拷贝,不同的进程只需把自己的虚拟内存映射过去就行了,节省了大量内存
- 虚拟空间内存中需要分配连续空间,而物理内存中并不需要,可以利用碎片
0x06 总结
以上所说的基本上涵盖了程序从编写到执行的整个过程了,叙述的有点宽泛,单页有限,类似编译过程中的语法树、链接中的动静态链接以及延迟绑定等特性、程序装载执行中MMU如何负责物理内存映射等都没有详细阐述,以后再填坑把。感叹自己还是学的太慢,之前操作系统课的时候冷嘲热讽,其实殊不知错失了很多学习更多东西的机会,还是NAIVE,233333333。